논문:
https://dl.acm.org/doi/pdf/10.1145/3448016.3457294
옛날엔 노션에서 복붙이 됐는데 이젠 안 되네요... 어쩔 수 없이 마크다운으로 내보낸 다음 복붙했습니다.
가독성이 좀 안 좋아도 이해 부탁드립니다!
# Introduction
### 문제 상황 - Hotspot
- Hotspot: 작은 수의 레코드(tuples)가 집중적으로 읽히거나 쓰이면서 동시에 여러 트랜잭션이 해당 레코드를 경쟁하는 상황
- 이런 hotspot은 전체 실행 시간 중 일부만 차지하지만, 그 전체 트랜잭션은 Blocking 상태로 만들어 병렬성 저하
### 한계 - 2PL
- Hotspot은 잠깐 쓰이고 끝나더라도, strict 2PL에서는 트랜잭션이 커밋될 때까지 모든 락을 유지해야 함
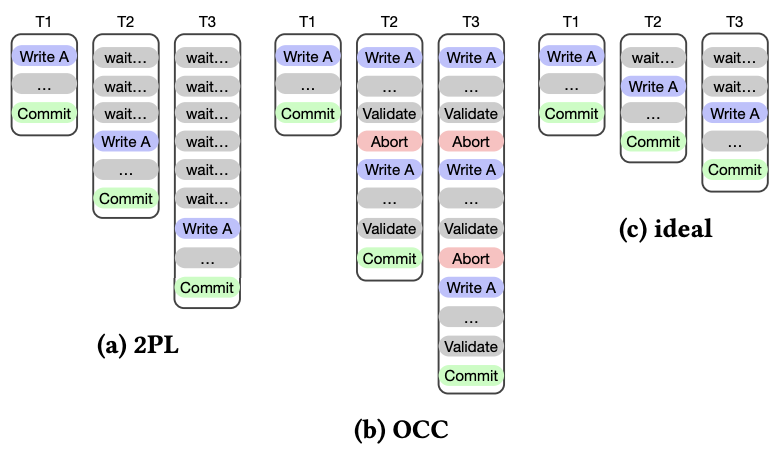
- (a) 2PL: 선행 트랜잭션이 커밋되어 락을 풀 때까지 기다려야 함
(b) OCC: 커밋 단계에서 충돌 감지(Validation) 후 abort
(c) Ideal: A를 사용하는 부분만 직렬화를 하고, 나머지 트랜잭션은 병렬 수행
⇒ “Hotspot 자체가 아니라 트랜잭션 전체를 병렬화 하지 못하는 게 근본적인 Bottleneck 이다”
### 선행 연구
- MS Orleans, IBM IMS/VS, Hekaton, MOCC, CormCC, 등…
- 대부분 Hotspot에 특화된 최적화 또는 Transaction Chopping 등을 시도
- Ideal 실현 불가능했던 이유:
1. 기존 방식들은 Dirty Read 불가능하도록 제한
2. 2PL 위반 없이 병렬화 실현 불가능
# 2. Background and Motivation
## 2.1. Two-Phase Locking (2PL)
### 2PL
- 동일 데이터에 대해 충돌(Conflict) 동시 허용X
- Growing Phase(락 획득)과 Shrinking Phase(락 해제, 획득 불가능)
- ⇒ Lock Dependency Graph에 사이클이 생기지 않을 수 있도록 역할
⇒ Serializability(직렬 가능성) 보장
### Deadlock 대처 방식
- Deadlock Detection
- Wait-For Graph를 구성하여 주기적으로 사이클 여부 체크
- 고병렬 하드웨어에서는 이 그래프가 Bottleneck이 됨
- Deadlock Prevention
- 락 획득 조건을 사전에 정하여 사이클이 아예 생기지 않도록
- ex. Wound-Wait
### Wound-Wait Variant
- 작동 방식
- 트랜잭션 시작 시 Timestamp를 할당
- 작을수록(빠를수록) 높은 우선순위
- T1←T2 충돌 발생 시,
1. T2의 ts가 더 작으면, 현재 락 보유자 abort (Wound)
2. 아니면, 락을 기다림 (Wait)
- Wound-Wait vs Wait-Die
- Wait-Die
- 우선 순위: Old(T1) > Young(T2)
- Old는 young을 기다릴 수 있지만, Young은 old 못 기다리고 abort (young←old 대기만 가능)
- Starvation 가능성 낮음(young이 반복 abort)
- 구현 간단
- Wound-Wait
- Old는 young을 abort, young은 old를 기다림 (old←young 대기만 가능)
- Starvation 거의 없음(항상 old가 우선권)
- wait queue 구현 필요
- 구현 구조
- `owners`: 현재 락을 소유하고 있는 트랜잭션 리스트
- `waiters`: 락을 기다리는 트랜잭션 리스트(ts 순 정렬)
- 장점
- Deadlock-Free: 모든 edge가 일관된 순서를 가지므로 cycle이 없음
- Starvation-Free: 오래된 트랜잭션은 절대 wound 당하지 않음
- Wound-Wait은 Google Spanner에서도 사용되는 검증된 방식이다
(Bamboo는 wound-wait 기반의 2PL에서 동작)
## 2.2. Transaction Chopping
- 트랜잭션을 여러개의 sub-transaction으로 쪼갠다
- 각 sub는 수행이 끝난 후에 자기 변경 내용을 다른 트랜잭션에 볼 수 있게
(Dirty Read 가능하게)
- sub는 짧은 시간동안만 Lock을 보유하므로 hotspot contention 감소
### 구현 방식: SC-Graph (Sibling-Conflict)
- 여러 개의 sub로 나뉘었을 때, 그들 사이의 실행 순서를 어떻게 정할지를 나타내는 그래프
- 구성
- `node`: sub-transaction
- `S-edge`: 같은 트랜잭션 내에서 sub들을 연결
- `C-edge`: 다른 트랜잭션 간에 잠재적인 충돌이 있는 경우 연결
- 제약 조건
- 사이클이 없어야 하며, 첫 번째 sub만 abort 가능해야 함
- 첫번쨰 sub abort면 전체 롤백시키면 됨
- 하지만 중간 sub가 abort면 이전 sub의 결과가 노출되었을 수 있으므로 상당히 복잡해짐
### 최신 연구 성과: IC3
- Column-Level static analysis
- 같은 테이블의 다른 칼럼 접근은 충돌X
- Runtime dependency tracking
- 실행 중에 동적으로 트랜잭션 간 dependency를 추적하여 commit 순서 강제
- Optimistic Execution
- 충돌 가능성이 낮은 트랜잭션들은 validate/commit 단계에만 순서를 맞추고 그 외 구간은 병렬 수행
### 한계점
1. 워크로드 정적 분석
- 모든 트랜잭션의 정볼르 사전에 알고 있어야 함
- 새로운 쿼리 등장 시, 전체 분석 다시 해야 함
2. 보수적인 충돌 우려
- 잠재적인 conflict 가능성만으로 sub를 하나로 병합
- ex. 서로 다른 튜플을 접근해도 같은 칼럼이면 C-edge로 판단
3. Deadlock prevention 제약
- C-edge는 교차되면 안 됨 → 일부 쿼리는 반드시 묶여야 함
- ⇒ Chopping의 granularity 제한
# 3. Bamboo
- S2PL 위반
- commit 되기 전에 Lock을 **retire**(조기 해제)하고
- Dirty Read 허용
## 3.1. Challenges of Violation 2PL
### (1) Dependency Tracking
- 기존의 2PL은 lock 자체가 트랜잭션 간 의존성을 관리한다
- 하지만 Bamboo는 dirty read를 허용 → 기존 락 기반의 wait-for graph만으로는 모든 의존성 추적 불가능
- Ex)
- T1(Write)←T2(Dirty-Read) && T2(Write)←T1(Dirty-Read) (사이클)
- 하지만 락을 기다린 게 아니라 기존 방식으로는 감지 불가능
### (2) Cascading Aborts
- T1(Write)←T2(Dirty-Read), T1이 abort하면 T2도 abort 필요
- 잘못 관리되면 리소스 낭비 및 성능 급감
## 3.2. Protocol Description
### 핵심 데이터 구조
- `tuple.retired`
- 어떤 트랜잭션이 final-write 후 더이상 사용하지 않는 경우 `owners`→`retired`로 옮김
- retired 리스트 안에서는 dirty-read 의존성 추적 가능
- `txn.commit_semaphore`
- 커밋되기 전까지 의존성이 해소되었는지를 나타냄
- dirty read 한 트랜잭션은 이 값이 0이 될때까지 커밋을 기다림
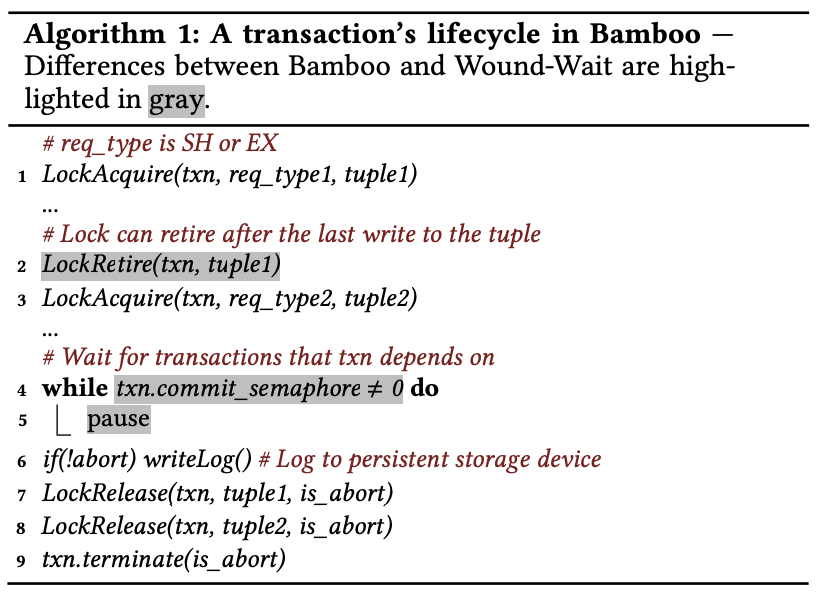
### Locking Functions
- `LockAcquire(txn, req_type, tuple)`
- 기존 Wound-Wait과 거의 동일 + retired 리스트에도 충돌 검사
- 충돌 시, low priority trx를 wound
- `LockRetire(txn, tuple)`
- owners → retired 이동
- 다른 트랜잭션에 dirty-read 허용
- retired 리스트 안의 순서로 dirty-read 의존성 추적 가능
- `LockRelease(txn, tuple, is_abort)`
- EX_LOCK을 가진 채로 abort 하면, cascading abort
- 뒤 트랜잭션의 `commit_semaphore--;`
- `PromoteWaiters()`
- lock의 waiters 리스트에서 conflict가 없는 트랜잭션을 owners로 승격
- retired와의 conflict가 있으면 `commit_semaphore++;`

## 3.3. Deciding Timing for Lock Retire
- 언제 LockReitre()를 호출할지
- Final write 라면, 즉시 retire 가능
- 하지만 프로그램 흐름 상 다시 접근할 가능성이 있다면 그걸 분석해서 안전한 시점에만 retire 해야 함
### Solution: 프로그램 분석 + 조건절
- Bamboo는 control/data flow를 분석하여 어느 시점이 safe-to-retire인지 결정
- *Bamboo can rely on programmer annotation or program analysis to find the last write and insert lock_retire() after it*
- 필요한 조건을 자동으로 생성하여 해당 조건이 true일 때만 retire 할 수 있도록
- Ex)
- 바닐라: Update(tup1) → 조건에 맞으면 → Update(tup2)
```cpp
LockAcquire(table1, tup1, EX); // op1
... // other queries and computations
tup2.key = f(input);
if (cond)
LockAcquire(table1, tup2, EX); // op2
```
- 만약, tup1==tup2 면?
- 이때 op1 직후에 LockRetire 하면 잘못된 동작이 될 수 있음
- Bamboo: 안전한 조건을 분석 후 LockRetire()를 조건부로 실행
```cpp
LockAcquire(table1, tup1, EX); // op1
... // other queries and computations
tup2.key = f(input);
**if (!cond || (cond && tup1.key != tup2.key))** // synthesized condition
LockRetire(table1, tup1);
... // other queries and computations
if (cond)
LockAcquire(table1, tup2, EX); // op2
```
## 3.4. Discussion
### Fault Tolerance
- commit 전에 로그 flush → 특별한 장애 복구 처리 필요 없음
### Phantom Protection
- 일반적인 next-key locking 그대로 사용 가능
### Weak Isolation
- serializability 보다는 낮은 단계 제공
- Repeatable Read: phantom 방지
- Read Committed: shared lock은 조기에 release
- Read Uncommitted: retire이 곧 relase로 간주
### Other Variants of 2PL
- Bamboo는 어떤 2PL과 잘맞는가?
- Bamboo는 기본적으로 wound-wait 위에서 동작하지만 wait-die 등에도 적용 가능
- 이하 생략
### 📌 예: Wound-Wait vs. Wait-Die
### ✅ Wound-Wait (기본)
- **트랜잭션 시작 시 timestamp 부여**, 오래된 트랜잭션일수록 우선순위 높음
- 새 트랜잭션이 락 요청 시, 자신보다 **늦은 트랜잭션을 abort시킬 수 있음**
- **deadlock-free**, **starvation-free**
### ❌ Wait-Die
- 마찬가지로 timestamp 기반
- **오래된 트랜잭션은 기다릴 수 있지만**, **젊은 트랜잭션은 abort되어야 함**
- 즉, **항상 "old waits for young"만 허용**
> “When applying retiring and dirty reads to this setting, the older transactions are subject to cascading aborts, meaning an unlucky old transaction may starve and never commit.”
>
- 문제: Bamboo에서 dirty read를 허용하게 되면,
- 젊은 트랜잭션이 먼저 쓰고 → 오래된 트랜잭션이 그것을 읽게 됨 (T1 → T2)
- 나중에 젊은 트랜잭션(T2)이 abort되면, **오래된 T1도 abort되어야 함**
- 이건 Wait-Die의 근본 정책인 **"old > young" 우선순위** 를 위반하게 되고,
- 반복적으로 **오래된 트랜잭션이 cascading abort → starvation** 발생 가능
> “Such problems do not exist in Wound-Wait.”
>
- Wound-Wait는 애초에 **높은 우선순위의 트랜잭션이 낮은 트랜잭션을 abort 시키는 구조**이므로,
- 이런 식의 역전된 dirty-read 의존성이 잘 발생하지 않고, **safe하고 starvation도 없음**
### Compatibility with Underlying 2PL
- LockRetire()를 호출하지 않으면 기존 S2PL과 완전히 동일하게 동작 (dirty read 허용 여부)
- 즉, 시스템은 상황에 따라 동적으로 Bamboo 사용 가능 (Flexibility)
- Ex. hotspot에만 사용하고 다른 트랜잭션에서는 사용X
### Opacity
- 커밋되기 전에도 트랜잭션 내부에서 보는 모든 읽기는 일관되어야 한다는 성질
- 특정 트랜잭션에 opacity가 필요하면 그 트랜잭션만 bamboo 끄면 됨
## 3.5. Optimization for Bamboo
1. Read는 즉시 retire
- cascading abort를 유발하지 않으므로 latch 없이 바로 retire 해도 됨
2. 마지막 쯤의 write는 retire 하지 않음
- benefit이 적고 cascading abort 가능성이 높으므로 skip
3. Read-Write 충돌로 인한 abort 제거
- 기존 Bamboo
- T1(write, retired) ← T2(read): 충돌
- 우선순위가 낮은 T1이 abort 될 수도
⇒ 불필요한 abort
- Bamboo는 read/write 시 local copy를 유지 (dirty version)
- T2는 T1의 dirty 값을 기다리지 않고, T1이 가지고 있는 최신 값을 read-only 복사본으로 안전하게 읽을 수 있음
- read는 락 소유 여부와 관계 없이 local copy만 있으면 실행 가능
→ abort 안 해도 됨, read 후 write 도 가능
4. 첫 충돌 시점에 동적으로 Timestamp 할당
- 실제 충돌이 발생한 시점에만 ts 할당 (Lazy Timestamp Allocation)
- CAS(compare-and-swap)을 통해 중복 없이 ts 할당 (lock-free)
# 4. Cascading Aborts
## 4.1. Cases Inducing Cascading Aborts
### 언제 abort가 발생하는가?
1. Wound by higher-priority txn: 오래된 트랜잭션이 젊은 트랜잭션 강제 중단
2. Cascading Abort: 의존성에 따라 abort (bamboo에서 추가된 것)
3. Application-level or integrity abort: 논리적 조건 위반, 유저 요청 등
## 4.2. Effects of Cascading Aborts as a Trade-off of Reducing Blocking
- Blocking 줄이기 vs Cascading Abort 증가의 trade-off
### 비용 측정 지표
1. Abort Chain Length: cascading abort되는 트랜잭션 수
2. Abort rate: 전체 트랜잭션 중 abort 비율
3. Abort time: abort된 트랜잭션이 낭비한 총 CPU 시간
4. Wait Time: 기존 2PL에서 lock을 기다리는 데 낭비되는 시간
- wait time을 줄이는 대신, abort time을 늘리는 방향으로 진행
1. dirty read를 안 했으면 어차피 기다릴 거였음 → Bamboo는 시도라도 가능
2. abort된 트랜잭션은 데이터를 읽고 CPU 캐시를 채움 → 다음 실행에서는 더 빠르게 실행
- 이 효과는 Silo 같은 시스템에서 이미 관측됨
- 수학적 모델링 (생략)


- 모델에 따르면, 보통 데이터 수(D)가 동시 실행 트랜잭션 수(N)보다 훨씬 크므로 대부분 Bamboo가 이득
# 5. Experiment Evaluation
## 5.1. Experimental Setup
- 트랜잭션 처리 방식
1. Stored Procedure Mode: 사전에 트랜잭션 경로 고정
2. Interactive Mode: 클라이언트가 step-by-step으로 호출(현실적, 고비용)
- 실험 대상 프로토콜
1. Wound-Wait (기존 2PL)
2. No-Wait (충돌 즉시 abort)
3. Wait-Die
4. Silo (OCC 기반)
5. IC3 (Chopping 기반)
- 환경
- DBx1000 (인메모리 DBMS)
- 서버: Intel Xeon, 15~32 core, 1000GB DRAM
- Dataset: 수백MB~100GB 이상
## 5.2. Bamboo without Cascading Aborts (Single Hotspot)
### Single Hotspot at Beginning
- 워크로드: 16 random read + 초반의 1 read-modify-write hotspot
- 결과
- Procedure Mode: 6배 성능 향상 vs Wait-Die (best performing 2PL based-protocol)
- 이유:wait time 절약
- Interactive Mode: 7배 성능 향상 vs Wound-Wait(best basline)
### Varying Transaction Length
- 최대 19배 속도 향상
### Varing Hotspot Position
- Hotspot이 앞쪽에 있을수록 성능 차이 큼
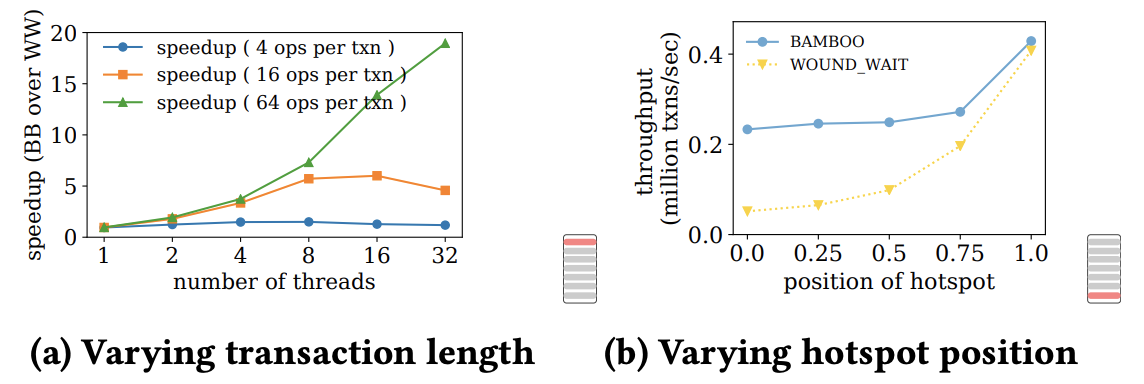
## 5.3. Bamboo with Cascading Aborts (Multiple Hotspots)
- Hotspot을 2개로 늘려 cascading abort가 발생할 수 있도록 설계
- 두 hotspot 사이의 거리를 조정하며 실험
- 거리가 멀어질수록 dirty read, cascading abort 가능성, retire 효과 증가
- 목적: wait time과 cascading abort 간의 trade-off 확인
### 실험 1: 첫 hotspot 고정, 두 번째 hotspot 이동

- BAMBOO-base: optimization2 제거 (불필요한 retire 회피)
- (a) Bamboo가 항상 우수
- x=0.75, bamboo가 37% 우수, abort는 72% 증가

- A_ww: Wound-Wait에서 lock-wait time (1/2)
A_bb: Bamboo에서 기다리는 시간 (1/16)
P_conflict: 충돌 발생 확률
B_bb: Bamboo에서 abort time
P_cas_abort: cascading abort 확률
- ≥ 0.217 ⇒ 최소 21.7% 정도 성능이 우수
- (b) speed up trade off: More aborts, Less blocking
- bamboo가 3배 속도 향상
- abort time이 증가했지만 총 시간에서의 비율이 작음
- bamboo-base는 마지막 hotspot까지 retire 하려고 해서 오버헤드 증가
- 간격이 멀어질수록 cascading abort 가능성 증가
### 실험 2: 첫 번째 hotspot을 이동

- 실험 1에 비해 bamboo에게 덜 유리한 조건
- (a) 전반적으로는 우수하지만 차이가 크지 않음
- 특히 x=0에 가까울수록, 성능 향상의 1/16 수준
- 그래도 여전히 lock-wait time은 줄이고 abort time으로 대체함
- (b) Bamboo의 abort time이 높아지긴 해도, WW의 lock-wait time을 넘지 않음
- 전체적으로는 Bamboo가 여전히 효울적
- abort가 cache warm-up 효과도 있음
- x=0.5에서 보면 abort time이 커보이지만 wait-time 보다는 작음
- 하지만 Bamboo-base는 성능이 더 나쁨
- bookkeeping, commit-semaphore 관리 오버헤드만 발생
- Bookkeeping overhead
retire할 때마다 Bamboo는 다음 작업들을 수행해야 합니다:
- `owners → retired` 리스트 이동
- `retired` 리스트 정렬
- 이 리스트의 상태에 따라 **후속 트랜잭션의 dependency (commit_semaphore++) 계산**
- 모든 변화가 thread-safe하게 처리되어야 함 → **락, 원자 연산 필요**
- 즉, Optimization 2는 이런 상황에서 중요하다
- 위 수식에서 x=0일 때, A_ww랑 A_bb랑 거의 유사해짐
- 이럴 땐 abort overhead가 상대적으로 커져서 base 성능 저하
## 5.4. Experiments on YCSB
- YCSB 벤치마크
- Yahoo! cloud serving benchmark
- 대규모 웹 서비스 환경을 시뮬레이션 하는 표준 벤치마크
- 랜텀 key-value 스타일 엑세스 수반
- Hotspot 충돌 실험에 매우 적합
- 데이터: 1억개 튜플, 총 100GB 이상
- 각 튜플은 PK 1개 + 100Byte 문자열 10개 칼럼
- 각 트랜잭션은 16개의 레코드 접근 → read or update
- θ (theta): 높을수록 hotspot이 생성됐다는 의미
- workload contention level
when θ = 0, all tuples have equal chances to be accessed.
When θ = 0.6 or θ = 0.8, 10% of the tuples in the database are
accessed by ∼40% and ∼60% of all transactions respectively.
### 실험 1: 스레드 수 변화 실험

- (a) 64 thread 까지는 성능 증가
- Wound-Wait 대비 최대 1.77배
- 96 thread부터 2PL 기반 프로토콜 성능 감소 이유: 2PL의 구조적 한계
- Lock thrashing: 락 경합이 너무 심해져 시스템이 락 처리에만 자원을 소모하고 실질적인 작업을 거의 못하게 되는 현상
- (b) Bamboo는 lock-wait time이 거의 없음 (abort는 있지만 낮은 비중)
- Silo는 abort rate이 높아서 이 stored-procedure 모드에서는 bamboo 보다 빠름 (cache warm-up)
### 실험 2: Long Read-Only Transaction 포함 실험

- 95% 일반 RW 트랜잭션(16튜플), 5%는 read-only(1000튜플)
- (a) Bamboo는 최대 5배 성능 향상
- Read-Only는 Write는 blocking하지 않아서 dirty-read 구조가 유리
(Optimization 3. read←write 가능)
- (b) Silo는 긴 트랜잭션이 starvation&abort 되어 runtime이 길어짐
- thread=120, Bamboo는 no-wait보다 긴 트랜잭션 커밋률이 20% 높음
### 실험 3: Read Ratio 변화 실험
- Bamboo는 read ratio가 증가할수록 abort 감소, dirty read 효과 커짐
- 전 구간에서 기존 2PL 계열보다 27%~71% 성능 우위
### 실험 4: θ 변화 실험

- θ ↑ (hotspot 증가) → 성능 gain 증가
- θ > 0.7, Wound-Wait 대비 72% throughput 향상
- lower contention에서는 10% 성능 하락 (overhead)
- 하지만, interactive 모드에서는 성능 하락이 크지 않음
(network communication - expensive gRPC calls)
- θ ≤ 0.8, 최대 8% 성능 우수, WW대비 2배 속도 향상
- Silo: Stored-Procedure Mode에서는 2PL 기반보다 더 빠름(low-level 최적화, abort warm-up)
- Bamboo: Interactive Mode에서는 모든 프로토콜 중 최고 성능
## 5.5. Experiments on TPC-C Results
- High contention 환경에서 성능이 우수함을 입증한 뒤, 실세계의 복잡한 트랜잭션 유형에서도 실험
- 실험 환경
- New-Order 50% (1%는 강제 abort, 현실적인 유저 abort 시나리오 반영)
- Payment 50%
### 실험 1: Varying Thread 실험

- (a) Bamboo: WW 대비 최대 2배 향상
- Silo: abort는 많지만 cache warm-up 때문에 가장 빠름
- (b) Bamboo: WW 대비 최대 4배, Silo 대비 최대 14배 성능 향상
- Interactive 모드에선 abort에 고비용(네트워크)
### 실험 2: Varing Warehouse 실험

- (a) Warehouse=1, Bamboo가 WW 대비 최대 2배 빠름
- (b) 모든 warhouse에서 최고 성능 유지
- WW, Silo 대비 최대 4배 향상
- Wait 제거와 abort 감소 효과가 매우 크다
## 5.6. Comparison with IC3
- IC3: Transaction Chopping 기반 시스템
- 트랜잭션을 column-level 단위로 정적 분석하여 충돌 가능성이 있는 연산만 순차적으로 실행
- Optimistic Execution: 실행은 병렬, 검증 시 충돌 있으면 abort
### 실험 1: Original New-Orders
- NewOrder와 Payment가 서로 다른 칼럼 업데이트 (잠재적인 충돌)

- (a) IC3는 정적 분석 때문에 실제 충돌이 없다고 판단하고 많은 병렬성 확보
→ Bamboo보다 우수
- (b) IC3가 Bamboo보다 abort 많음
### 실험 2: Modified New-Orders
- 둘 다 w_ytd 칼럼 업데이트 하도록 변경
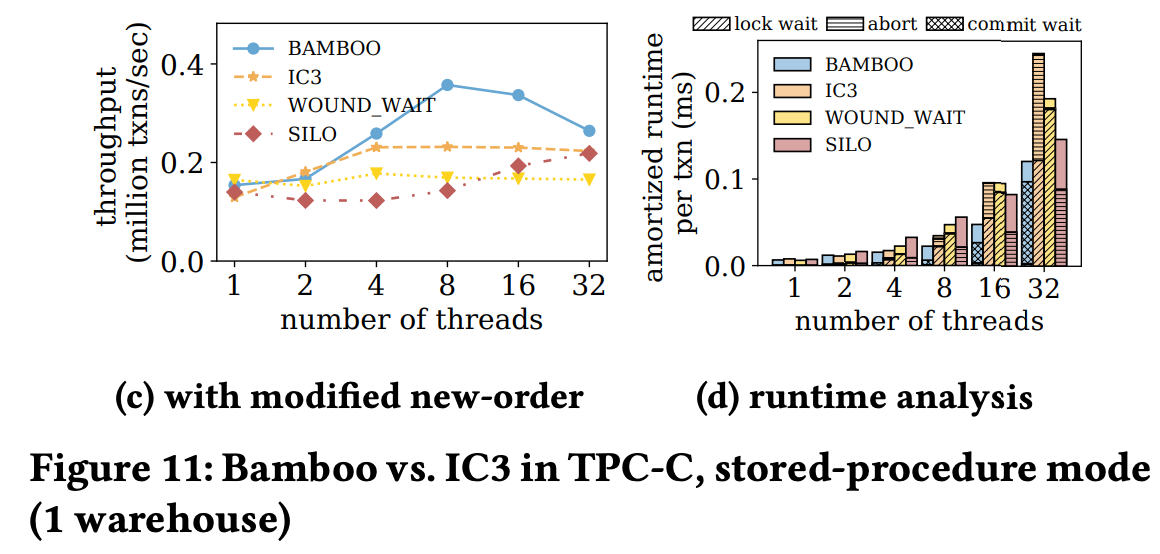
- (c) Bamboo는 거의 영향을 받지 않음
- IC3: 모든 관련 연산을 순차 처리해야 함으로 병렬성 급감
- (d) IC3의 wait 시간이 훨씬 큼
- Bamboo는 IC3보다 1.5배 빠름
- 병목 원인
- IC3는 칼럼 기준 → 같은 칼럼이면 다른 튜플이어도 충돌로 간주
- Optimistic Execution은 abort 많음
# 6. Related Work
## 6.1. Violating Two-Phase Locking
- 2PL의 ‘락은 커밋 때까지 유지한다’라는 규칙을 위반하는 것
1. ELR (Early Lock Relase)
- commit 때, log flush 하는 동안 release
2. CLV (Controlled Lock Violation)
- ELR의 일반화 버전
- lock entry 안에 dependency를 명시적으로 관리 (retired list의 영감)
⇒ Bamboo는 실행 중에 lock 위반을 실시간으로 허용할 수 있다
## 6.2. Reading Uncommitted Data
- Dirty read 허용하는 것
1. Falerio et al. (2017)
- Deterministic DB에서 early write visibility 제안
- 고정된 트랜잭션 순서에서 dirty write를 읽어도 된다
2. Hekaton (MS SQL OLTP 엔진)
- MVCC 기반
- 특정 상태(ex. prepare 단계)일 때만 dirty read 허용
3. DRP (Deferred Runtime Pipelining)
- 일부 트랜잭션은 tame(접근 범위가 명확)
- tame trx부터 실행 → dirty read 기반 병렬성 확보
⇒ Bamboo는 determinism 없이도 dirty read 가능 (사전 분석 불필요)
## 6.3. Transaction Scheduling
- 트랜잭션 실행 순서를 재배열해서 병렬성과 효율성을 높이자
1. Quro
- 트랜잭션 내부 연산 순서를 바꾸어 hotspot이 뒤에 오게 조정
- 락 홀딩 시간을 줄이는 방식
2. Ding et al. (VLDB ‘18)
- 트랜잭션 간 순서를 재배열 해서 conflict 최소화
- NP-hard 문제를 근사하는 greedy 알고리즘 사용
⇒ Bamboo는 데이터 의존성에 따라 트랜잭션 순서를 조정할 필요 없음
이 분야는 논문이 워낙 드문드문 나와서 아주 소중한 논문이었던 것 같습니다..
'DB' 카테고리의 다른 글
| [MySQL/InnoDB] Update와 Insert의 Locking, Blocking(대기) - 코드를 중심으로 (2) | 2024.09.30 |
|---|---|
| [논문리뷰] Controlled Lock Violation (SIGMOD’13) (2) | 2024.09.30 |
| [MySQL] ERROR: Another process with pid ~ is using unix socket file. (0) | 2024.09.30 |
| [MySQL] Rollback Pointer 기반의 MVCC 이해하기 - 코드 중심으로 (1) | 2024.02.06 |
| [MySQL] 전문검색 FullText Search 기능 이용해 검색 구현하기 - AWS RDS innoDB 8.0.28 (0) | 2022.09.14 |